
Fallstudie: Parallelisierung einer Partikel-Simulation
-
 c/o Jessica Hausberger
c/o Jessica Hausberger
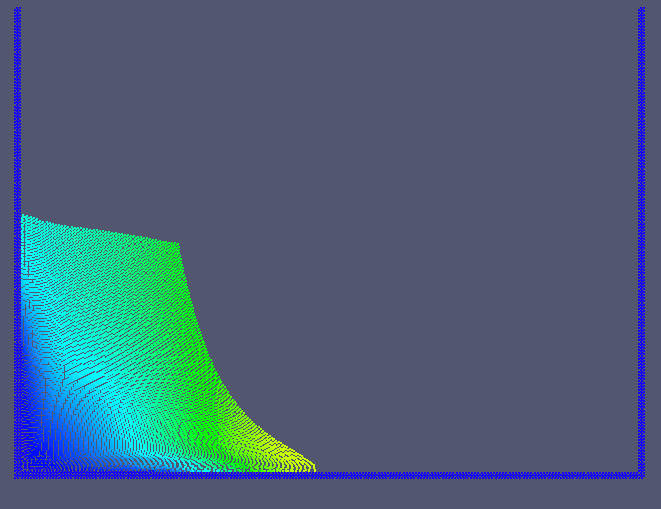
 Partikel-Simulation (SPH) des Dambreak-Problems. Die Methode ist besonders für Strömungen mit komplexen Geometrien oder freien Oberflächen geeignet.
Partikel-Simulation (SPH) des Dambreak-Problems. Die Methode ist besonders für Strömungen mit komplexen Geometrien oder freien Oberflächen geeignet.
Ein Kunde im Hochschul-Bereich hatte einen inhouse-Code (C++) zur Berechnung komplexer Strömungen entwickelt. Die verwendete Partikelmethode (SPH - smoothed particle hydrodynamics) ist besonders zur Simulation von geometrisch komplexen Strömungen mit freien Rändern geeignet. Aufgrund der Charakteristik der simulierten Prozesse kam es zu sehr kleinen Zeitschritten und damit langen Laufzeiten. Daher sollte der Code parallelisiert werden; die Zielplattform war eine Intel Xeon Multi-core CPU mit 12 cores.
Analyse
Aus Effizienzgründen werden im SPH-Algorithmus die Interaktionen zwischen Partikeln paarweise berechnet. Eine naive Parallelisierung der Aufsummierung der Interaktionen würde damit im Falle von shared memory zu massiven Datenkonflikten und falschen Ergebnissen führen. Es mussten daher anspruchsvollere Parallelisierungs-Ansätze entwickelt werden.
Da nicht a priori klar war, welche Strategien sich als performant erweisen würden, entwickelten wir gemeinsam mehrere Parallelisierungsstrategien, die jeweils an 4-5 Stellen (Schleifen) im Programm zum Einsatz kamen. Dabei erwies sich die Ausnutzung der spezifischen Lokalitätseigenschaften des Problems als hilfreich.
-


 c/o Jessica Hausberger
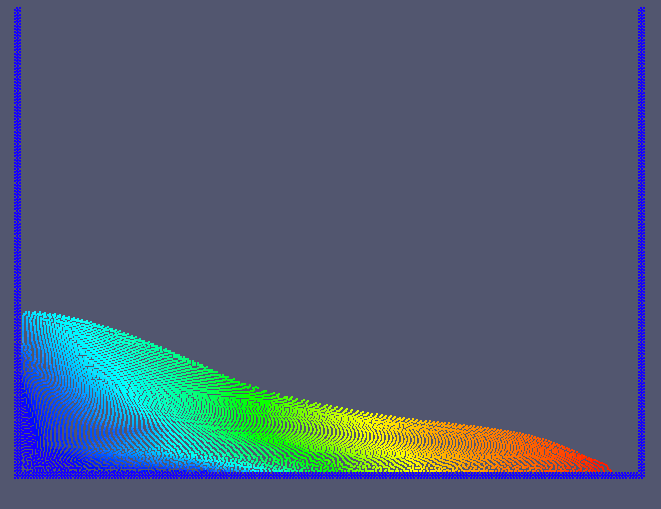
Blockbildung ist ein verbesserter Ansatz zur Parallelisierung des SPH Algorithmus. Blöcke mit derselben Nummer (Farbe) können unabhängig voneinander bearbeitet werden, ohne Synchronisation.
c/o Jessica Hausberger
Blockbildung ist ein verbesserter Ansatz zur Parallelisierung des SPH Algorithmus. Blöcke mit derselben Nummer (Farbe) können unabhängig voneinander bearbeitet werden, ohne Synchronisation.
Umsetzung
Als parallele Umgebung wurde OpenMP gewählt, da dies weit verfügbar und portabel ist. Durch Abstraktion und Einsatz von Methoden der generischen Programmierung gelang es, die parallele Implementierung für jede Strategie durch jeweils eine einzige generische Routine bereitzustellen, die dann (jeweils passend parametrisiert) an den verschiedenen Stellen des Programms verwendet werden konnte. Dadurch war es ohne großen Aufwand möglich, zwischen den verschiedenen Ansätzen umzuschalten und diese zu vergleichen. Weiterhin erlaubte dieser Ansatz eine weitgehende Entkopplung des algorithmischen Codes vom parallelen Framework. Damit wäre ein Umstieg von OpenMP auf z.B. C++11 Threads mit wenigen lokalisierten Änderungen möglich.
Resultate
Es wurden mehrere Varianten untersucht und verglichen. Während die einfacheren Methoden, die explizite Synchronisation mittels atomics einsetzten, auf 12 Kernen immerhin einen Speedup von ca. 8x erreichten, kamen die besten, allerdings algorithmisch komplexeren Ansätze auf eine Beschleunigung von etwas unter 11x, unter Verwendung von Hyperthreading mit 24 threads sogar auf knapp 15x.
Die Ergebnisse wurden u.a. auf der Konferenz "Parallel 2013" präsentiert.